Table of Contents
Update February 8, 2018
All the work, plus submitting several URLs for indexing, plus doing a trick, caused the crawler to read 1,643 pages on the 5th.
Index coverage stats, however, only go to the 5th, not the day after, so it’s still not possible to know what effect our changes had. Still, the other work in the past seems to have had some effect. The number of excluded pages continues to decline, and indexed pages increases.
I’ve started to track this in a spreadsheet.
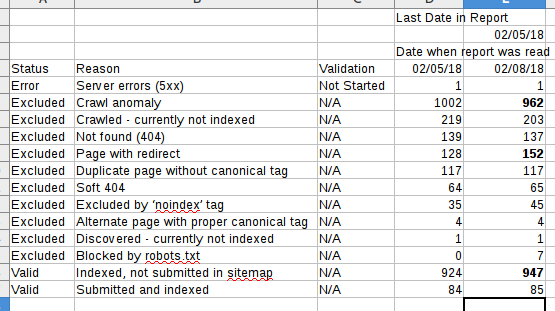
Indexed pages increased by 20.
The number of “crawl anomaly” pages dropped by 40. Pages with redirects increased by 24; that means our redirects are working.
The “noindex” tag is causing more pages to be excluded. That’s what we wanted.
“Crawled, not indexed” means that the pages got read, but haven’t been put into the search index. I think this is like a work queue. I hope the 1600+ pages crawled don’t show up in here.
I want those pages to cause the “redirect” count to increase. I’m hoping 404s decline, as well.
Clicks seem to be improving, but I really cannot tell. They have always been pretty low.
Trick to Boost the Crawl
In the Search Console, you can request to reindex a page, and then crawl all the links from that page.
What I did was create a page called the Page of Doom, and put all the links I wanted to “kill” in there. It totaled around 1000 links, from the “crawl anomaly” report.
These were links that now had a 301 redirect, or returned a 420, or some other status code other than 404. Some 301 redirects went to the matching page. Most went to the home page. A few went to another website. Some URLs didn’t have anywhere to go, and returned a “Gone” status code.
I downloaded the URLs from the “crawl anomaly” report, and then did some string concatenation with the spreadsheet, to produce a list of HTML links.
The code was copied into the page, and then the page was submitted to Google. Google then went into it. I’m not sure why it crawled an additional 600 pages, but that’s a nice bonus.